Scalable Multi-Engine Data Profiler
Producing deterministic, highly structured database intelligence to give AI agents the deep context they need to write perfect SQL.
Why ?
While building Aiden (an AI Data Engineer), we realized LLMs hallucinate SQL when they only see column names. They need to know that a status column only contains 'OPEN' and 'CLOSED', or that a revenue column has no negative values.
Every database speaks a different dialect. Snowflake uses NUMBER(10,2), DuckDB uses HUGEINT. Fetching this at scale without crashing the warehouse is a massive engineering challenge. This profiler acts as the universal translator and orchestrator to pull this deep context reliably.
"How do we extract statistical metadata (histograms, cardinality, null ratios) across completely different data warehouses without dealing with mismatched data types or timeout crashes on massive schemas?"
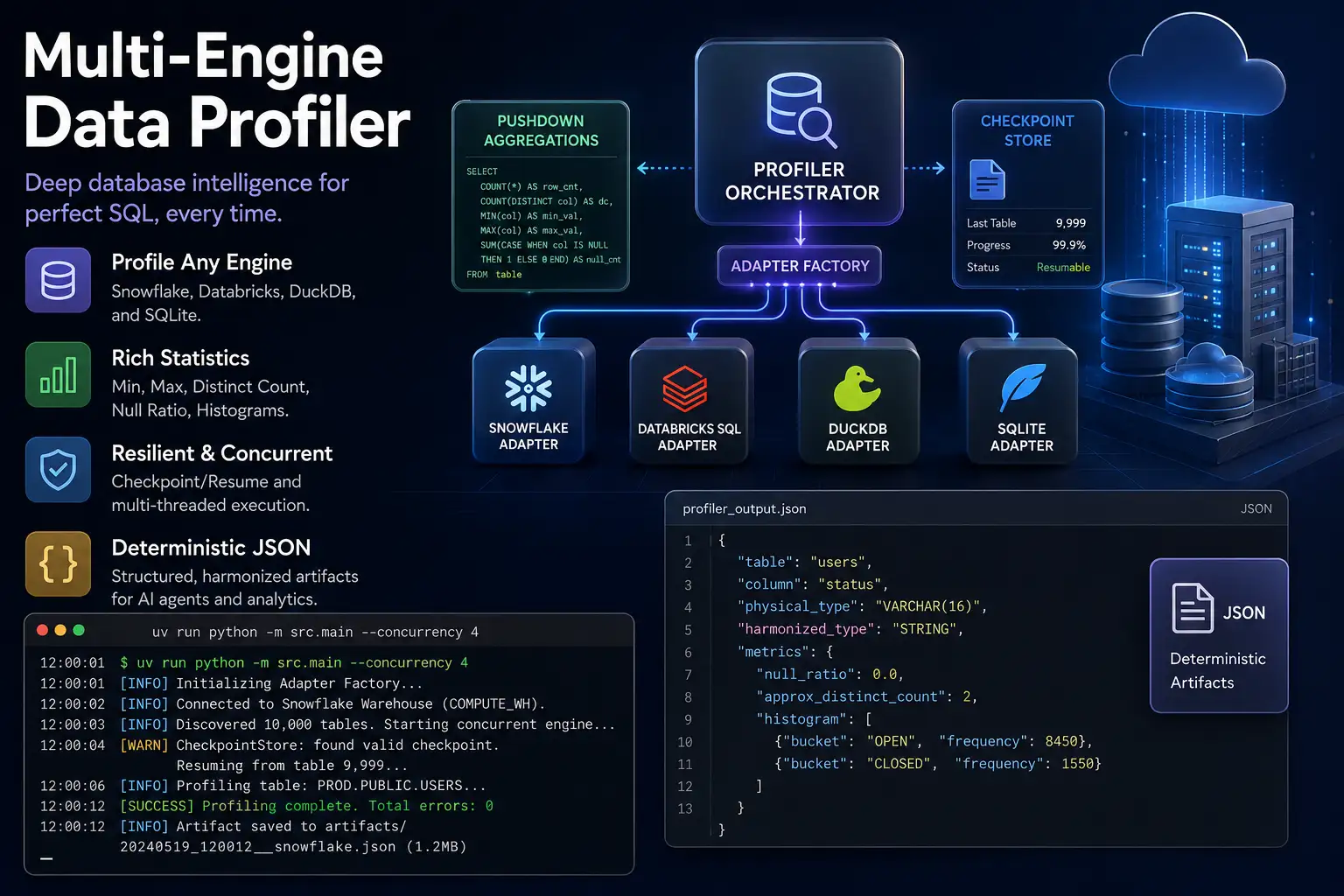
Architecture & The Adapter Pattern
If tomorrow we need to support PostgreSQL or BigQuery, the core orchestrator doesn't change-we simply write a new Adapter. The Adapter Factory dynamically dispatches queries to the underlying engine while pushing heavy statistical aggregations directly down to the warehouse.
from abc import ABC, abstractmethodfrom pydantic import BaseModelclass DatabaseAdapter(ABC):@abstractmethoddef get_tables(self, schema: str) -> list[str]:pass@abstractmethoddef profile_column(self, table: str, col: str) -> dict:pass{"table": "users","column": "status","harmonized_type": "STRING","metrics": {"null_ratio": 0.0,"approx_distinct_count": 2,"histogram": [{"bucket": "OPEN", "frequency": 8450},{"bucket": "CLOSED", "frequency": 1550}]}}Resilience & Context Harmonization
Profiling 10,000 tables takes time. If the network drops at table 9,999, you shouldn't have to start over.
The engine runs concurrent threads but strictly updates a checkpoint.json file, allowing it to seamlessly resume exactly where it left off.
Notice the harmonized_type in the output artifact. It maps proprietary database types (like Snowflake's NUMBER) into a universal taxonomy, standardizing context for the downstream LLM agents.
Production-Grade DevEx
Tooling choices were made prioritizing speed, strict validation, and maintainability:
- uv: Lightning-fast dependency management & virtual environments.
- Pydantic v2: Strict data validation ensuring the output JSON always conforms to the expected schema.
- Ruff & Pyright: Blazing fast linting and strict static typing.